For those in the Ceph community you’ve probably heard many times that “hardware RAID is dead”, don’t use it, use software data protection that’s built into the filesystem architecture.
In general, it’s true, hardware RAID is dead, you shouldn’t be ordering a Broadcom RAID card in a modern server and filesystems like Ceph (and notably OpenZFS) eliminate the need for hardware RAID and they both have advanced error correction features like bit-rot detection and auto-correction.
So why would you want it, in what scenarios does it start to make sense to include an additional layer of data protection and durability into a storage cluster using hardware (or software) RAID? The main scenarios we see in the field are 1) cloud level durability for large clusters, 2) simplified maintenance, 3) greater scalability, 4) reduced power consumption, and 5) elimination of short IO pauses when a cluster device (OSD) fails.
All of the above really apply to large clusters so if you’re building a cluster under 5PB or so you probably need not read further. Also, an additional hardware RAID layer should not replace having cluster durability at the Ceph filesystem layer (EC and/or replica) but rather should augment it to add a second layer of durability.
That said, lets go through these benefits more detail..
Public Cloud Durability
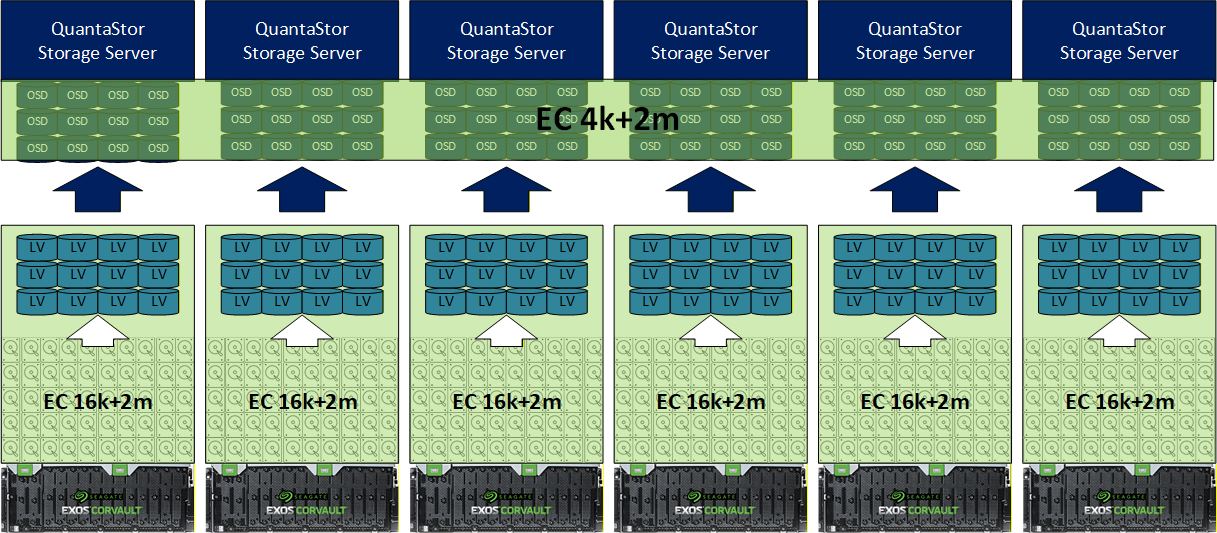
When you look at public cloud storage providers you’ll find that they all have multilayer architectures. In a multi-layer architecture there’s local data protection (RAID or EC) making it so device repair/rebuild are local and then a distributed cluster wide EC and/or replicas layer that spans the cluster to handle individual node, rack, and site outages.
When doing the Markov chain analysis to determine the number of 9s of durability you get the results are pretty surprising. Where a single layer architecture might bring 6x 9s of durability (99.9999%) a double layer design with both layers bringing 6x 9s of durability combines to deliver 14x 9s of durability (99.999999999999%) and higher. This is critical at scale due to the number of devices involved and the cost impact of any downtime.
At no time does the Ceph cluster ever see any health issues due to bad media (OSDs are built from fault-tolerant virtual devices) and there’s no network load to do the rebuild/resilvering, its all local. This is important when the cluster is all in one site but becomes even more important when you have a multi-side ‘metro-cluster’ deployment.

Simplified Maintenance
Replacing bad media is the most common hardware maintenance task. As such, it is important to keep it simple. Pulling a bad device with a blinking LED and putting in a new device to replace it is low maintenance and that’s what it is like to replace bad media in a system like the Seagate Corvault. IT organizations can easily train their staff on the process and no current Ceph skills are required, the whole problem is factored out.
No reweighting, no PG remap storms, no backfill network spikes, no delayed rebalancing. From the cluster’s perspective, nothing happened.
Greater Scalability
The general guidance for Ceph clusters is to keep the cluster under 4000 devices (OSDs) or so to keep it simple and to avoid having to do specialized tuning. 4000x of the latest 30TB HDDs comes to about 120PB. When you look at the annual device failure rate of ~2% (average for HDDs) that equates to 80x device failures per yar in a 4000x device cluster and about 2x failed devices per week. That’s a lot, and with the PB being the new TB the 120PB limit can be constraining. So how do we go big? Storage virtualization. When you bring a hardware RAID layer in below the OSDs you are able to reduce you cluster device count and meet the same capacity goals. For example, if you use a hardware RAID like a Seagate Corvault to produce 100TB LUNs your 4000x OSDs in the cluster are now delivering 400PB (100TB x 4000) of storage for the same number of devices. This translates to 3x to 5x greater scalability. Does this come into play for a typical cluster, no, but something important to think about at scale.
Reduced Power Consumption
This ties into the point above on greater scalability. When designing a Ceph cluster you need to allocate a certain amount of CPU and RAM to each device (OSD) you add to the cluster. If you have a storage virtualization layer that is aggregating space into larger 100TB virtual devices that in effect reduces the RAM and CPU requirements because you’re producing 3x to 4x fewer OSDs for the same capacity cluster. For example a 4000x device cluster using JBODs would need 4000x 4GB = 16TB of RAM so that all the OSD service instances can have 4GB each. In contrast, if you deployed 4000x devices using Seagate Corvault smart JBODs you’d produce virtual devices (LUNs) that are larger, say 120TB for round numbers which means you’d need 4x less RAM or 4TB of RAM for the whole cluster rather than 16TB of RAM.
This is because the Corvault aggregates drives internally to produce virtualized block devices which Ceph OSDs see as just regular devices and in turn the OSD density per node drops by 2x to 5x depending on how big you make the virtual devices.
This same math for the reduction in required RAM also plays out for CPUs and this means you can often reduce the total number of storage servers in the cluster as well. In short, less nodes, less RAM, less CPU, it all adds up to a lot of power savings not to mention major capital cost saving which is important given current times with NAND and RAM shortages driving prices up.
Eliminate the Stun
When a device fails in a Ceph cluster the monitors detect this by seeing that the OSD service associated with the device has gone offline, is not responding, or is reporting a media failure. In such a case the cluster monitor marks the OSD as ‘down’ within some number of seconds (example, 15 sec) and then if the device is ‘down’ for a set period of time (eg. 1 hour) it will then get marked as ‘out’. The issue is that initial 15 seconds. It is tunable so you could reduce it to 10 or even 8 seconds of ‘peering’ but you do not want it to be too low else you’ll get devices marked ‘as ‘down’ that shouldn’t be. But for that short period of time IO is delayed to any client trying to read a block of data that is on the media that is in the middle of a transition from ‘active’ to the ‘down’ state. For most deployments, this isn’t an issue, applications are designed to handle IO delays and even VMware can handle IO delays up to 90 seconds but some applications, especially those running cloud services for large user bases a 10 sec delay is too long. The fix? Add a layer of durability under the OSDs. Using hardware or software RAID you’ll have no delay, no stun when a device fails. This is a fairly niche case but its a real one I’ve run into in the field and it’s a good fix.
Summary
This article is really not about compensating for Ceph weaknesses, it’s about architectural scaling. Most small to medium sized clusters don’t need and shouldn’t use multiple layers of durability as it’s typically not worth the cost but as clusters get large it’s important to start looking at a layered architecture just like the public cloud service providers do for their storage.
Questions, comments? Write us at info (at) osnexus.com for more information and if you’re looking for a great place to start in designing your next storage cluster check out our our solution design tools at osnexus.com/design be sure to checkout the latest QuantaStor at osnexus.com/downloads.
I’m the CEO & co-founder of OS NEXUS, a storage appliance software company with a focus on scale-out storage management. We do a lot of hardware and software storage technology integration on Linux with our QuantaStor Software Defined Storage (SDS) platform this blog is our way to share some thoughts and insights on these technologies and where we’re headed with SDS.
Leave a Reply